
Artificial intelligence (AI) continues to fast-track modern tech capabilities. Decades of research and developments in data and computer science have enabled these wins.
Within this exciting field sits machine learning (ML). This dedicated discipline trains machines to emulate or even outperform human intelligence based on input data.

Potential application areas for ML solutions are driving exciting innovations industry-wide. It expedites the development of pharmaceutical discovery, financial forecasting, and disease diagnosis.
Its benefits to business and wider society have seen a new demand for talent and expertise. The need to meet shifting consumer trends and transform operational norms means ML job positions are cropping up everywhere.
In this article, we’ll provide 50 ML interview questions employers expect answered when applying for a position as a machine learning analyst or scientist. We’ll also offer expertly crafted answers to help prospective candidates prepare for the role.
What is machine learning?
ML is a subset of AI that focuses on teaching machines to identify relationships between data. ML involves training algorithms and statistical models to make autonomous outputs based on data it ingests and analyzes.
Unlike pre-programmed systems, ML solutions can “learn” from data to make predictions, recognize objects, and detect patterns precisely. This flexibility and adaptability allow systems to be designed to solve several unique and specific problems.
ML models can be supervised, unsupervised, or rely on a blend of both methods. The former involves learning from clearly labeled and classified data. The latter includes ML systems that can read and make distinctions from unlabeled data.
Deep learning (DL) is a subset of ML that extends its techniques. DL combines neural networks with multiple layers to perform complex data exploration. It excels at identifying patterns and structures within unlabeled data. Its architecture draws inspiration from the function of the human brain, making it particularly powerful for unsupervised learning tasks.
Basic concepts
To start, let’s explore potential interview questions employers might ask about the basic concepts of machine learning.
Q1: What is the difference between supervised and unsupervised learning?
Example answer: Supervised learning involves training models with labeled data to accurately predict outcomes. Unsupervised learning explores patterns in unlabeled data without predefined targets.
Tip: Employers will ask for practical examples or projects where you’ve applied supervised and unsupervised learning techniques. This is to gauge your hands-on experience and understanding of different ML applications.
Q2: Define overfitting and underfitting in machine learning models.
Example answer: Overfitting occurs when a model becomes overly sensitive to noise or irrelevant details in the training data, diminishing the performance of new data. Underfitting arises when a model is too simplistic to capture the complexities of the data.
Tip: Be prepared to discuss specific strategies you’ve used to address overfitting or underfitting challenges in your ML projects. This demonstrates your ability to remedy problems when optimizing model performance.
Q3: What is a confusion matrix, and why is it useful?
Example answer: A confusion matrix provides a clear visual representation of a classification model’s performance. This helps determine where it correctly predicts outcomes and where it falls short.
Tip: Employers may inquire about instances where you’ve used confusion matrices to evaluate and refine models. Prepare to discuss your ability to assess models and derive insights for improvements.
Q4: Explain precision and recall.
Example answer: Precision measures the accuracy of positive predictions. This indicates how reliably a model identifies outcomes as positive. Recall assesses a model’s ability to detect all positive instances. This methodology emphasizes its thoroughness in capturing relevant data patterns.
Tip: Here, detail scenarios where precision and recall metrics influenced your decision-making in model selection or tuning. This showcases your analytical approach to evaluating model performance.
Q5: What is the bias-variance tradeoff?
Example answer: The bias-variance tradeoff involves balancing a model’s flexibility (variance) with its ability to capture underlying data patterns (bias). Models with high bias may oversimplify, while those with high variance may overfit the training data.
Tip: Discuss your strategies for managing the bias-variance tradeoff in model development. This demonstrates your ability to optimize model complexity for better predictive accuracy.
Q6: Describe the process of cross-validation.
Example answer: Cross-validation is a thorough technique for assessing model reliability. It divides data into subsets for training and validation to ensure that models generalize well to new data sets.
Tip: Share experiences where cross-validation has strengthened your confidence in model performance and reliability. Describe your approach to validation techniques. This will demonstrate your commitment to delivering accurate and dependable solutions.
Q7: What is the purpose of regularization in machine learning?
Example answer: Regularization techniques prevent overfitting by penalizing complex models that fit closely to training data. Doing so promotes better generalization to new datasets.
Tip: This is where you provide concrete examples of implementing regularization methods to enhance model generalization and stability. Detail innovative approaches taken to regularization. Underscoring your ability to improve model performance through effective regularization strategies is key.
Q8: How does a decision tree algorithm work?
Example answer: Decision tree algorithms iteratively split data based on significant features. This creates hierarchical structures capable of both classification and regression tasks.
Tip: Consider impactful examples of these techniques driving actionable insights or solutions. For example, you can discuss optimizing decision tree structures to boost business outcomes. This will help showcase your expertise in algorithmic applications.
Q9: What is ensemble learning? Provide examples.
Example answer: Ensemble learning involves leveraging the strengths of each model and minimizing their weaknesses. This is done by combining multiple models to improve predictive accuracy. For example, many decision trees are built in a Random Forest, and their outputs are averaged, strengthening predictive performance. Another example is a Gradient Boosting Machine. These models are built sequentially, each correcting the errors of its predecessor. Stacking is also a popular ensemble technique. This involves training a meta-model to combine the predictions of several base models.
Tip: Share specific projects where you successfully implemented ensemble learning. How did it lead to improved results? Discuss the challenges you faced and how you overcame them. This demonstrates your practical knowledge and problem-solving skills in applying ensemble techniques.
Q10: Explain the concept of a learning rate in gradient descent.
Example answer: The learning rate in gradient descent controls how quickly model parameters adjust in response to error gradients. It directly influences the speed and effectiveness of model optimization during training.
Tip: Share your strategies for optimizing learning rates for optimal model convergence and performance. Here, you can discuss your approach to fine-tuning gradient descent algorithms. This will show your expertise in driving model training and achieving a high standard of predictive accuracy.
Algorithms and techniques
This section will equip you to handle questions about the algorithms and techniques of machine learning. These are the nuts and bolts that power these intelligent systems.
Q11: Compare and contrast linear regression and logistic regression.
Example answer: Linear regression predicts continuous outcomes by fitting a line to the data. It minimizes the difference between actual and predicted values. Logistic regression is for binary classification problems. It predicts the probability that an observation belongs to a category using the logistic function, which outputs values between 0 and 1.
Tip: Employers often look for practical applications. What scenarios required you to use each technique effectively? For example, explain how linear regression helped forecast sales trends and how logistic regression classified customer behaviors.
Q12: How does the k-means clustering algorithm work?
Example answer: K-means clustering partitions data into k clusters. It initializes k centroids and assigns each data point to the nearest centroid. Centroids are recalculated based on the designated points. This continues until centroids change insignificantly.
Tip: Think of projects where k-means clustering uncovered hidden patterns in customer data. Highlight how these insights, like targeted marketing or product development, drove strategic decisions.
Q13: What are support vector machines (SVM), and how do they work?
Example answer: SVMs are used for classification tasks. They find the optimal hyperplane that separates different classes in the data. This maximizes the margin between the closest points of each class, which are known as support vectors.
Tip: Detail times when you’ve used SVMs, perhaps in image recognition or text classification. Discuss feature selection and parameter tuning to achieve the best performance.
Q14: Explain the working of a random forest algorithm.
Example answer: A random forest algorithm creates multiple decision trees and combines their results. Each tree is trained on a random subset of data and features. The final output is determined by averaging (for regression) or voting (for classification) the outputs of all trees.
Tip: Did you improve prediction accuracy using random forest methods? Provide examples. Discuss how its robustness to overfitting made it preferable over a single decision tree in that scenario.
Q15: Describe the Naive Bayes algorithm.
Example answer: The Naive Bayes algorithm is based on Bayes’ Theorem. It assumes features are independent given the class label. Despite this simplification, it performs well in text classification and spam detection.
Tip: Talk about a project where Naive Bayes was your algorithm of choice due to its simplicity and efficiency. Describe how you prepared your data, particularly in preprocessing steps like tokenization and stop-word removal.
Q16: What is gradient boosting?
Example answer: Gradient boosting builds models sequentially. Each new model corrects the errors of the previous ones. It combines weak learners, typically decision trees, to create a strong predictive model that improves accuracy over time.
Tip: Give a specific example where gradient boosting led to substantial performance gains. Discuss the importance of choosing appropriate learning rates and regularization techniques to avoid overfitting.
Q17: Explain the concept of principal component analysis (PCA).
Example answer: PCA is a dimensionality reduction technique. It transforms data into orthogonal components, capturing the most variance with the fewest components. This simplifies the dataset while retaining essential information.
Tip: Describe examples where PCA was used for handling high-dimensional data. Explain how it improved model performance by reducing overfitting and speeding up the training process.
Q18: How does a neural network function?
Example answer: A neural network consists of layers of interconnected nodes or neurons. Each neuron processes inputs and passes the result to the next layer. Through training, the network adjusts connection weights to minimize errors in predictions.
Tip: Discuss your experience with neural networks in projects like image classification or natural language processing. Highlight the architecture you used, such as CNNs or RNNs, and the challenges you overcame.
Q19: What is a convolutional neural network (CNN)?
Example answer: CNNs specialize in image and video processing. They use convolutional layers to learn spatial hierarchies of features from input images. This makes them especially useful for image recognition and object detection.
Tip: Did you partake in projects where CNNs achieved excellent results? Explain how you fine-tuned the network, including selecting layers and filter sizes, to enhance performance.
Q20: Describe recurrent neural networks (RNNs) and their use cases.
Example answer: RNNs are designed for sequence data, like time series or text. They have loops that allow information to persist. This makes them suitable for highly contextual tasks, like language modeling or machine translation.
Tip: Have you used RNNs in a specific project, such as time series forecasting or sentiment analysis? Discuss the significance of handling sequential data and any advanced techniques you employed, like Long Short-Term Memory (LSTM) networks.
Data preprocessing and feature engineering
Q21: Why is data normalization important in machine learning?
Example answer: Data normalization scales features to a common range, usually between 0 and 1. This ensures that all features contribute equally to the model’s learning process. Without normalization, features with larger ranges can disproportionately influence the model. This can lead to skewed outputs. Normalization improves the convergence speed during training and enhances overall model accuracy.
Tip: When discussing normalization, consider emphasizing a case where it was critical for improving model performance. Mention specific challenges you encountered and how normalization was a pivotal solution.
Q22: Explain the concept of feature selection.
Example answer: Feature selection is identifying the most relevant features in a dataset. This helps reduce model complexity, improve performance, and prevent overfitting. By focusing on important features, models can learn more effectively and produce better predictions. Feature selection techniques include filter, wrapper, and embedded methods.
Tip: Highlight your strategic thinking when selecting features. Discuss any analytical tools or methods you used and how your choices led to a more streamlined and accurate model.
Q23: What are outliers, and how can they be detected?
Example answer: Outliers are data points that significantly differ from other observations. They can distort model training and lead to inaccurate predictions. Outliers can be detected using statistical methods such as z-score, visualization tools, or machine learning algorithms such as Isolation Forest.
Tip: Reflect on a situation where outliers critically impacted your analysis. Describe how identifying and addressing them improved your model’s overall integrity and reliability.
Q24: Describe various techniques for handling missing data.
Example answer: Handling missing data can be approached through deletion, imputation, or using algorithms that accommodate missing values. Deletion removes records with missing data but can lead to information loss. Imputation fills in missing values using methods like mean, median, mode, or more sophisticated approaches like k-nearest neighbors. Some algorithms can handle missing data directly.
Tip: Share your insights on balancing data loss and accuracy trade-offs. Discuss a specific project where your chosen method for handling missing data significantly impacted the final model.
Q25: What is one-hot encoding, and when is it used?
Example answer: One-hot encoding converts categorical variables into a binary matrix. Each category is represented by a unique binary vector, making it suitable for algorithms that require numerical input. This method prevents the model from misinterpreting categorical data as having ordinal relationships.
Tip: Mention a time when one-hot encoding was essential for a project’s success. Explain how it helped to accurately represent categorical data and why it was preferable to other encoding techniques in that context.
Q26: How do you handle imbalanced datasets?
Example answer: Handling imbalanced datasets includes leveraging a few techniques, such as resampling, adjusting class weights, or using specialized algorithms. Resampling can be done by oversampling the minority class or undersampling the majority class. Adjusting class weights can help models learn more effectively. This can be done by penalizing misclassifications of the minority class more heavily.
Tip: Recall a challenging project where class imbalance was a major issue. Detail how you addressed it and the improvement in model performance as a result. Highlight any innovative approaches you used to ensure balanced training.
Q27: Explain the term “feature scaling.”
Example answer: Feature scaling standardizes the range of independent variables or features of data. This process helps models that rely on distance calculations to perform better by ensuring that no single feature dominates the others. This includes k-nearest neighbors or gradient descent-based algorithms,
Tip: Provide insights on a project where feature scaling was critical. Explain how it enhanced model performance. What specific scaling method did you choose? (e.g., standardization vs. normalization).
Q28: What is the difference between L1 and L2 regularization?
Example answer: L1 regularization (Lasso) adds the absolute value of the magnitude of coefficients as a penalty term to the loss function, leading to sparse models with few coefficients. L2 regularization (Ridge) adds the squared magnitude of coefficients as a penalty term, leading to smaller coefficients. Both methods help prevent overfitting by penalizing large coefficients.
Tip: Illustrate your understanding by explaining a situation where you applied L1 or L2 regularization. Describe the outcomes and why you chose one method over the other.
Q29: How do you deal with categorical variables in machine learning?
Example answer: Categorical variables can be handled using techniques like one-hot encoding, label encoding, or ordinal encoding. The choice of method depends on the nature of the categorical variable and the specific requirements of the model being used. Proper handling ensures that the model correctly interprets categorical data without introducing biases.
Tip: Emphasize a project where dealing with categorical variables was particularly complex. Explain your approach and the resulting improvements in model accuracy and interpretability.
Q30: What are some common techniques for feature extraction?
Example answer: Common techniques for feature extraction include Principal Component Analysis (PCA) and linear Discriminant Analysis (LDA) to create meaningful features. It also involves using domain-specific knowledge. These techniques help reduce dimensionality and improve model performance by focusing on the most informative aspects of the data.
Tip: Think of instances where feature extraction was instrumental. Discuss what techniques led to better model results. How did they help simplify the dataset while retaining essential information?
Model evaluation and validation
Q31: How do you evaluate the performance of a regression model?
Example answer: Evaluating a regression model involves using metrics like Mean Squared Error (MSE) and R-squared to measure prediction accuracy and model fit to data. MSE quantifies prediction errors by averaging squared differences between predicted and actual values, while R-squared indicates how well the model explains data variability.
Tip: Discuss practical applications where you applied MSE and R-squared to refine predictions. Doing so showcases your ability to use statistical metrics to optimize model performance.
Q32: What is AUC-ROC, and how is it interpreted?
Example answer: AUC-ROC assesses binary classifier quality by plotting the True Positive Rate against the False Positive Rate at varying thresholds. A higher AUC value indicates better classifier performance in distinguishing between classes.
Tip: Demonstrate your strategic approach to threshold optimization by illustrating your AUC-ROC understanding with specific examples of how you utilized it to enhance classifier effectiveness.
Q33: Explain the significance of F1 score.
Example answer: The F1 score balances Precision and Recall in binary classification. This provides a single metric to evaluate model accuracy across uneven class distributions.
Tip: Describe instances where you optimized the F1 score to achieve balanced classification performance. Employers must know you’re capable of tailoring models for effective real-world applications.
Q34: What are precision-recall curves?
Example answer: Precision-recall curves illustrate the trade-offs between Precision and Recall at different thresholds in binary classification. They provide insights into model performance across various decision boundaries. This is to determine how well the model identifies relevant instances while minimizing false positives.
Tip: Discuss practical applications where you analyzed precision-recall curves to optimize model performance. Describe how these curves guided your decision-making in setting classification thresholds.
Q35: How do you determine the optimal number of clusters in k-means clustering?
Example answer: Determining the ideal number of clusters in k-means clustering involves techniques like the Elbow Method and Silhouette Analysis. The Elbow Method helps identify the point where adding more clusters does not significantly improve model fit. Silhouette Analysis assesses the quality of clustering by measuring how similar each point is to its own cluster compared to others.
Tip: Provide examples of where you applied the elbow method and silhouette analysis to refine solutions. Discuss how these techniques informed your clustering strategy. Your ability to derive meaningful insights from data segmentation will enhance decision-making.
Q36: Describe how you would use a confusion matrix to evaluate a classifier.
Example answer: Using a confusion matrix involves summarizing the performance of a classification model. It does this by tabulating predictions versus actual outcomes across different classes. It provides key metrics such as True Positive, True Negative, False Positive, and False Negative rates. This provides a detailed assessment of model accuracy and error types.
Tip: Explain specific cases where you interpreted confusion matrices to evaluate and improve classifier performance. Have insights from the confusion matrix guided adjustments in model thresholds or feature engineering?
Q37: What is the importance of the train-test split in model evaluation?
Example answer: The train-test split partitions data into training and testing sets to validate model performance on unseen data, ensuring model generalizability and mitigating overfitting risks.
Tip: Ensuring model reliability and validity is a key requirement. Employers will expect a basic understanding of how a balanced train-test split can achieve this. Here, share how you implemented effective data partitioning strategies to validate model performance.
Q38: How do you handle a class imbalance in classification problems?
Example answer: Managing class imbalance in classification involves techniques to improve model accuracy and mitigate bias. This includes resampling (oversampling or undersampling) and algorithmic adjustments.
Tip: Successfully managing class imbalance is key to improving model performance. Describe how you applied resampling techniques or algorithmic adjustments to mitigate bias and optimize predictive accuracy.
Q39: What are some common performance metrics for classification models?
Example answer: Common performance metrics for classification models include Accuracy, Precision, Recall, F1 score, and AUC-ROC, each providing unique insights into model effectiveness.
Tip: Have you selected and interpreted performance metrics to evaluate classifier efficacy? Explain how you tailored metric choices based on project goals and stakeholder requirements.
Q40: Explain how cross-validation helps in model validation.
Example answer: Cross-validation enhances model validation by assessing performance across multiple data subsets, ensuring robustness and reducing overfitting risks.
Tip: A key skill is implementing cross-validation to validate and improve model robustness. Describe how cross-validation results influence model selection or parameter tuning.
Advanced topics and practical implementation
Q41: What is transfer learning, and when is it useful?
Example answer: Transfer learning enables leveraging knowledge from one machine learning task to enhance performance on another related task. This approach is valuable when data scarcity limits training for the target task. This ensures efficient knowledge transfer from a well-established source task.
Tip: Share specific times when you applied transfer learning to accelerate model development. Adaptability in optimizing machine learning solutions across diverse domains is a sought-after skill.
Q42: Describe the concept of reinforcement learning.
Example answer: Reinforcement learning involves models learning optimal behaviors through interaction with environments. This process includes receiving feedback as rewards or penalties, allowing agents to improve decision-making functions over time.
Tip: Think of experiences where you’ve implemented reinforcement learning algorithms to refine decision-making outputs. Adaptive and intelligent systems ensure flexibility. Let potential employers know you can get systems to this point.
Q43: What is a generative adversarial network (GAN)?
Example answer: A Generative Adversarial Network (GAN) comprises two networks, a generator and a discriminator. These two functions compete to generate realistic synthetic data. This architecture is instrumental in tasks requiring data augmentation or the generation of new samples.
Tip: Have you improved model robustness or generated synthetic data using GANs? Here’s where you should show your proficiency in advanced GAN techniques.
Q44: Explain the importance of hyperparameter tuning.
Example answer: Hyperparameter tuning optimizes pre-set parameters (like learning rates and batch sizes) to enhance model performance. Fine-tuning these parameters is critical for achieving optimal model convergence and accuracy.
Tip: Detail how you’d conduct hyperparameter tuning. This will emphasize your ability to achieve high ML performance through precise model tuning.
Q45: How do you deploy a machine learning model in production?
Example answer: Deploying a machine learning model involves transitioning it from development to operational environments. This process ensures scalability, reliability, and low-risk integration with existing systems.
Tip: Launch detailed models in production environments to address scalability and integration challenges. This proven ability to ensure scalability and integration strengthens your readiness to deliver end-to-end machine-learning solutions.
Q46: What is model interpretability, and why is it important?
Example answer: Model interpretability is needed to understand how machine learning models make decisions. Developing systems that are ingrained with trust and reveal biases is future-ready. It’s key that all stakeholders comprehend the model predictions’ rationale if they are to remain reliable solutions.
Tip: Think of a situation where you championed interpretable machine learning models. How did it help stakeholders make informed decisions?
Q47: Describe the role of an activation function in a neural network.
Example answer: Activation functions introduce non-linearity in neural networks, allowing them to model complex relationships between inputs and outputs. Functions like ReLU, Sigmoid, and Tanh influence learning capabilities and model performance.
Tip: Tailor your answer to the specific role. If the job description mentions specific network architectures (e.g., convolutional neural networks for image recognition), showcase your knowledge of relevant activation functions (e.g., ReLU for CNNs).
Q48: What is the purpose of dropout in neural networks?
Example answer: Dropout is a regularization technique that improves neural network generalization by randomly deactivating neurons during training. It mitigates overfitting by reducing the network’s reliance on specific neurons.
Tip: Don’t just state dropout’s effectiveness. Explain how it works. Connect the concept of randomly dropping neurons during training to preventing co-adaptation and promoting robust models. Show how this mechanism helps mitigate overfitting.
Q49: How do you approach a machine learning project from scratch?
Example answer: Initiating a machine learning project involves defining objectives, gathering data, selecting algorithms, training models, and deploying solutions. This process requires careful planning and adaptation to achieve the intended project outcomes.
Tip: Emphasize how you actively participated with stakeholders to understand the business problem and define success metrics. Show how you translated that knowledge into choosing the right machine-learning approach.
Q50: Explain the difference between batch and stochastic gradient descent.
Example answer: Batch gradient descent computes gradients across all training examples. It updates model parameters and ensures stable convergence. Stochastic gradient descent updates parameters incrementally after processing each example. This makes it faster and more suitable for large datasets.
Tip: Numbers speak volumes. Mention how your optimization strategy improved the project. For example, did it reduce training time by a specific percentage? Did it improve model performance on a key metric?
How to become the ideal candidate for future AI job positions
There is a clear business move towards AI and the various ways it can be leveraged to innovate and transform.
An abundance of data is only possible as information collection and storage capacities evolve, which has empowered R&D in ML solutions. This evolution opens new paths for business applications, driving efficiency and innovation.
Anticipating the demand for talent in both data and computer science fields is key. Those who understand these intersections are ideal candidates for future AI positions.
To stand out, focus on building a strong foundation in both technical skills and business acumen. Stay updated with the latest AI models and innovations. Develop strategic strength by bridging the gap between business and technology and showcase your ability to translate complex technical concepts into actionable business insights.
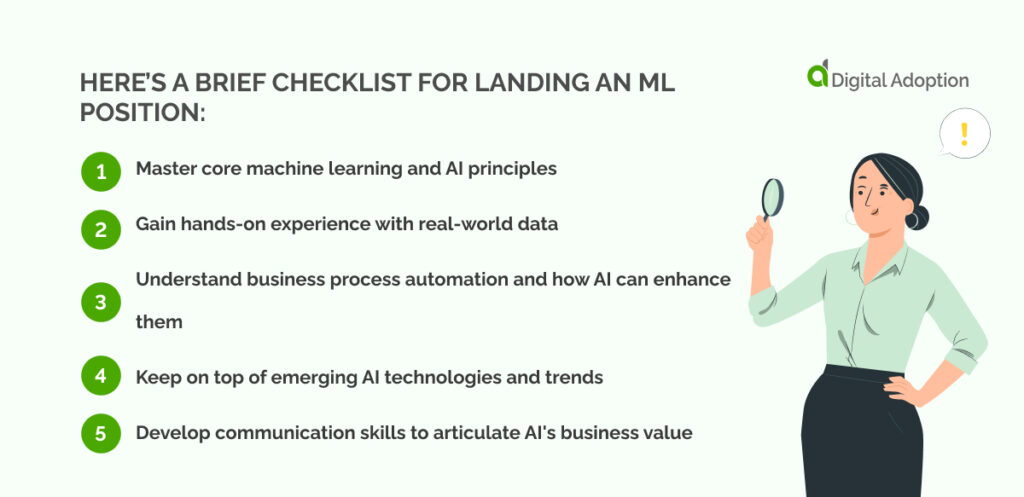
Here’s a brief checklist for landing an ML position:
- Master core machine learning and AI principles.
- Gain hands-on experience with real-world data.
- Understand business process automation and how AI can enhance them.
- Keep on top of emerging AI technologies and trends.
- Develop communication skills to articulate AI’s business value.
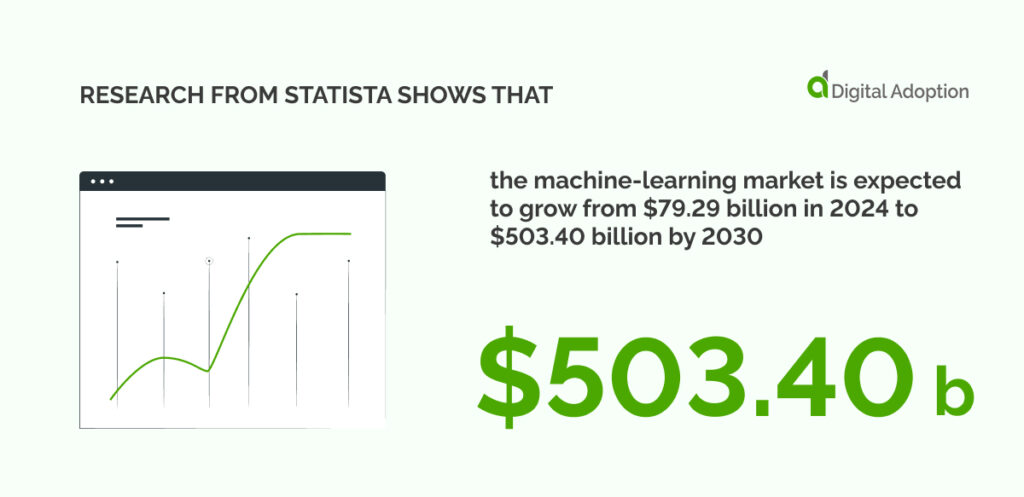
AI’s rise is assured. It’s full of exciting potential but comes alongside inherent risks. Implementing AI safely, securely, reliably, and responsibly is required for business success. Prioritize ethical considerations, robust data governance, and ongoing monitoring to navigate the complexities when deploying AI. Research from Statista shows that organizations worldwide are taking steps to manage risks from generative AI (GenAI). Nearly half of the companies monitor regulatory requirements, ensure compliance, and establish governance frameworks for GenAI tools and applications.
![4 Best AI Chatbots for eCommerce [2025]](https://www.digital-adoption.com/wp-content/uploads/2025/03/4-Best-AI-Chatbots-for-eCommerce-2025-img-300x146.jpg)


![13 Digital Transformation Enablers [2025]](https://www.digital-adoption.com/wp-content/uploads/2025/02/13-Digital-Transformation-Enablers-2025-img-300x146.jpg)


![4 Best AI Chatbots for eCommerce [2025]](https://www.digital-adoption.com/wp-content/uploads/2025/03/4-Best-AI-Chatbots-for-eCommerce-2025-img.jpg)

